


10. Listes▲
Ce chapitre présente l'un des types internes les plus utiles de Python, les listes. Vous pourrez également en apprendre plus sur les objets et ce qui peut arriver lorsque vous avez plus d'un nom pour le même objet.
10-1. Une liste est une séquence▲
Tout comme une chaîne, une liste est une séquence de valeurs. Dans une chaîne, les valeurs sont des caractères ; dans une liste, elles peuvent être de n'importe quel type. Les valeurs dans la liste sont appelées éléments.
Il existe plusieurs façons de créer une nouvelle liste ; la plus simple est d'entourer les éléments par des crochets ([ et ]) :
[10, 20, 30, 40]
['crunchy frog', 'ram bladder', 'lark vomit']Le premier exemple est une liste de quatre entiers. Le second est une liste de trois chaînes de caractères (décrivant les ingrédients appétissants entrant dans la fabrication de confiseries chocolatées dans un sketch des Monty Python : grenouille croquante, vessie de bélier et vomi d'alouette - NdT). Les éléments de la liste ne doivent pas nécessairement être du même type. La liste suivante contient une chaîne de caractères, un flottant, un entier, et (tiens !) une autre liste :
['spam', 2.0, 5, [10, 20]]Une liste à l'intérieur d'une autre liste est dite imbriquée.
Une liste qui ne contient aucun élément s'appelle une liste vide ; vous pouvez en créer une avec des crochets vides, [].
Comme vous pourriez vous en douter, vous pouvez affecter des valeurs aux variables de la liste :
>>> fromages = ['Cheddar', 'Edam', 'Gouda']
>>> nombres = [42, 123]
>>> vide = []
>>> print(fromages, nombres, vide)
['Cheddar', 'Edam', 'Gouda'] [42, 123] []10-2. Les listes sont modifiables▲
La syntaxe pour accéder aux éléments de la liste est la même que pour accéder aux caractères d'une chaîne - l'opérateur [] d'indexation. L'expression placée entre crochets spécifie l'indice.Rappelez-vous que les indices commencent à 0 :
>>> fromages[0]
'Cheddar'Contrairement aux chaînes de caractères, les listes sont modifiables. Lorsque l'opérateur d'indexation apparaît du côté gauche de l'affectation, il identifie l'élément de la liste auquel la valeur sera affectée.
>>> nombres = [42, 123]
>>> nombres[1] = 5
>>> nombres
[42, 5]L'un-ième élément de nombres, qui avait la valeur 123, a maintenant la valeur 5.
La Figure 10.1 montre le diagramme d'état pour fromages, nombres et vide :
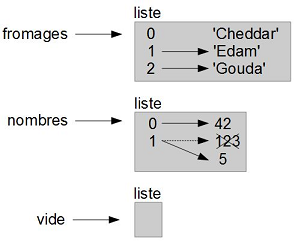
Les listes y sont représentées par des structures avec le mot « liste » à l'extérieur et les éléments de la liste à l'intérieur. fromages se réfère à une liste avec trois éléments indexés 0, 1 et 2. nombres contient deux éléments ; le diagramme montre que la valeur du second élément a été réaffectée de 123 à 5. vide se réfère à une liste sans aucun élément.
Les indices de liste fonctionnent de la même manière que les indices des chaînes de caractères :
- toute expression entière peut être utilisée comme indice ;
- si vous essayez de lire ou d'écrire un élément qui n'existe pas, vous obtenez une IndexError ;
- si un index a une valeur négative, il compte en sens inverse, à partir de la fin de la liste.
L'opérateur in peut également être utilisé sur des listes.
>>> fromages = ['Cheddar', 'Edam', 'Gouda']
>>> 'Edam' in fromages
True
>>> 'Brie' in fromages
False10-3. Parcourir une liste▲
La façon la plus courante de parcourir les éléments d'une liste est avec une boucle for. La syntaxe est la même que pour les chaînes de caractères :
for fromage in fromages:
print(fromage)Cela fonctionne bien si vous voulez juste lire les éléments de la liste. Mais si vous voulez écrire ou mettre à jour les éléments, vous avez besoin d'indices. Une façon courante de faire cela est de combiner les fonctions internes range et len :
Cette boucle parcourt la liste et met à jour chaque élément. len renvoie le nombre d'éléments dans la liste. range renvoie une liste d'indices allant de 0 à n - 1, où n est la longueur de la liste. À chaque passage dans la boucle, i prend la valeur de l'indice de l'élément suivant. L'instruction d'affectation dans le corps utilise i pour lire l'ancienne valeur de l'élément et pour lui attribuer la nouvelle valeur.
Le corps d'une boucle for sur une liste vide n'est jamais exécuté :
for x in []:
print("Ceci ne s'exécutera jamais.")Bien que la liste puisse contenir une autre liste, la liste imbriquée compte toujours comme un seul élément. La longueur de cette liste est quatre :
['spam', 1, ['Brie', 'Roquefort', 'Cheddar'], [1, 2, 3]]10-4. Opérations sur listes▲
L'opérateur + concatène des listes :
>>> a = [1, 2, 3]
>>> b = [4, 5, 6]
>>> c = a + b
>>> c
[1, 2, 3, 4, 5, 6]L'opérateur * répète une liste un nombre donné de fois :
>>> [0] * 4
[0, 0, 0, 0]
>>> [1, 2, 3] * 3
[1, 2, 3, 1, 2, 3, 1, 2, 3]Le premier exemple répète [0] quatre fois. Le second exemple répète la liste [1, 2, 3] trois fois.
10-5. Tranches de liste▲
L'opérateur de tranche [m:n] peut également être utilisé sur les listes :
>>> t = ['a', 'b', 'c', 'd', 'e', 'f']
>>> t[1:3]
['b', 'c']
>>> t[:4]
['a', 'b', 'c', 'd']
>>> t[3:]
['d', 'e', 'f']Si vous omettez le premier indice, la tranche commence au début de la liste. Si vous omettez le second, la tranche s'étend jusqu'à la fin de la liste. Donc, si vous omettez les deux, la tranche est une copie de la liste entière.
>>> t[:]
['a', 'b', 'c', 'd', 'e', 'f']Puisque les listes sont modifiables, il est souvent utile de faire une copie avant d'effectuer les opérations qui modifient des listes.
Un opérateur de tranche du côté gauche de l'affectation peut mettre à jour plusieurs éléments :
>>> t = ['a', 'b', 'c', 'd', 'e', 'f']
>>> t[1:3] = ['x', 'y']
>>> t
['a', 'x', 'y', 'd', 'e', 'f']Rappelons que l'opérateur de tranche de Python inclut l'élément de départ, mais exclut l'élément de fin de la tranche, si bien que la tranche [1:5] correspond à [1,2,3,4] (NdT).
10-6. Méthodes de listes▲
Python fournit des méthodes qui agissent sur les listes. Par exemple, append ajoute un nouvel élément à la fin d'une liste :
>>> t = ['a', 'b', 'c']
>>> t.append('d')
>>> t
['a', 'b', 'c', 'd']extend prend comme argument une liste et ajoute tous les éléments de celle-ci :
>>> t1 = ['a', 'b', 'c']
>>> t2 = ['d', 'e']
>>> t1.extend(t2)
>>> t1
['a', 'b', 'c', 'd', 'e']L'exemple ci-dessus ne modifie pas t2.
sort arrange les éléments d'une liste en ordre croissant :
>>> t = ['d', 'c', 'e', 'b', 'a']
>>> t.sort()
>>> t
['a', 'b', 'c', 'd', 'e']La majorité des méthodes de liste sont « vides » : elles modifient la liste et renvoient None. Si vous écrivez accidentellement t = t.sort(), vous serez déçu par le résultat.
10-7. Mapper, filtrer et réduire▲
Pour additionner tous les nombres d'une liste, vous pouvez utiliser une boucle de cette façon :
def additionner_tout(t):
total = 0
for x in t:
total += x
return totaltotal est initialisée à 0. À chaque passage dans la boucle, la valeur d'un élément de la liste est additionnée à la valeur de x. L'opérateur += fournit un raccourci pour mettre à jour une variable. Cette instruction d'affectation augmentée :
total += xest équivalente à :
total = total + xLors de l'exécution de la boucle, total accumule la somme des éléments ; une variable utilisée de cette façon s'appelle parfois un accumulateur.
L'addition des éléments d'une liste est une opération si commune que Python offre comme une fonction interne, sum :
>>> t = [1, 2, 3]
>>> sum(t)
6Une opération de ce genre qui combine une séquence d'éléments en une seule valeur s'appelle parfois une réduction.
Parfois, vous voulez parcourir une liste en construisant une autre. Par exemple, la fonction suivante prend une liste de chaînes de caractères et renvoie une nouvelle liste qui contient ces chaînes en majuscules :
def mettre_tout_en_majuscules(t):
res = []
for s in t:
res.append(s.capitalize())
return resres est initialisée à une liste vide ; à chaque tour de boucle, nous lui ajoutons l'élément suivant. Donc res est un autre genre d'accumulateur.
Une opération comme mettre_tout_en_majuscules est appelée parfois un map, car elle « mappe » (ou applique) une fonction (dans ce cas, la méthode capitalize) sur chacun des éléments d'une séquence.
Une autre opération commune est de sélectionner certains des éléments d'une liste et de renvoyer une sous-liste. Par exemple, la fonction suivante prend une liste de chaînes de caractères et retourne une liste qui contient seulement les chaînes en majuscules :
def seulement_majuscules(t):
res = []
for s in t:
if s.isupper():
res.append(s)
return resisupper est une méthode de chaîne de caractères qui renvoie True si la chaîne ne contient que des lettres majuscules.
Une opération comme seulement_majuscules s'appelle un filtre, car elle sélectionne certains des éléments et filtre les autres.
La plupart des opérations communes de liste peuvent être exprimées comme une combinaison de mappage, filtrage et réduction.
10-8. Supprimer des éléments▲
Il existe plusieurs façons de supprimer des éléments d'une liste. Si vous connaissez l'indice de l'élément que vous voulez supprimer, vous pouvez utiliser pop :
>>> t = ['a', 'b', 'c']
>>> x = t.pop(1)
>>> t
['a', 'c']
>>> x
'b'pop modifie la liste et renvoie l'élément qui a été supprimé. Si vous ne fournissez aucun indice, elle supprime le dernier élément et renvoie sa valeur.
Si vous n'avez pas besoin de la valeur supprimée, vous pouvez utiliser l'opérateur del :
>>> t = ['a', 'b', 'c']
>>> del t[1]
>>> t
['a', 'c']Si vous connaissez l'élément que vous souhaitez supprimer (mais pas son indice), vous pouvez utiliser remove :
>>> t = ['a', 'b', 'c']
>>> t.remove('b')
>>> t
['a', 'c']La valeur de retour de remove est None.
Pour supprimer plus d'un élément, vous pouvez utiliser del avec un indice de tranche :
>>> t = ['a', 'b', 'c', 'd', 'e', 'f']
>>> del t[1:5]
>>> t
['a', 'f']Comme d'habitude, la tranche sélectionne tous les éléments jusqu'au second indice, mais sans l'inclure.
10-9. Listes et chaînes de caractères▲
Une chaîne est une séquence de caractères et une liste est une séquence de valeurs, mais une liste de caractères n'est pas la même chose qu'une chaîne de caractères. Pour convertir une chaîne en une liste de caractères, vous pouvez utiliser la fonction list :
>>> s = 'spam'
>>> t = list(s)
>>> t
['s', 'p', 'a', 'm']Comme list est le nom d'une fonction interne, vous devriez éviter de l'utiliser comme nom de variable. J'évite également d'utiliser la lettre l, car elle ressemble trop au chiffre 1. Voilà pourquoi j'utilise t.
La fonction list décompose une chaîne de caractères en lettres individuelles. Si vous voulez découper une chaîne en mots, vous pouvez utiliser la méthode split :
>>> s = 'se languir de fjords'
>>> t = s.split()
>>> t
['se', 'languir', 'de', 'fjords']Un argument optionnel appelé délimiteur ou parfois séparateur spécifie quels caractères utiliser comme limites de mots. L'exemple suivant utilise un trait d'union comme séparateur :
>>> s = 'spam-spam-spam'
>>> delimiteur = '-'
>>> t = s.split(delimiteur)
>>> t
['spam', 'spam', 'spam']join est l'inverse de split. Elle prend une liste de chaînes de caractères et concatène les éléments. join est une méthode de chaîne de caractères, donc vous devez l'invoquer sur le délimiteur et passer la liste en paramètre :
>>> t = ['se', 'languir', 'de', 'fjords']
>>> delimiteur = ' '
>>> s = delimiteur.join(t)
>>> s
'se languir de fjords'Dans ce cas, le séparateur est un caractère espace, donc join insère un espace entre les mots. Pour concaténer des chaînes de caractères sans espaces, vous pouvez utiliser la chaîne vide, '', comme délimiteur.
10-10. Objets et valeurs▲
Si nous exécutons ces instructions d'affectation :
a = 'banane'
b = 'banane'Nous savons que a et b se réfèrent tous les deux à une chaîne de caractères, mais nous ignorons s'il s'agit de la même chaîne. Il existe deux états possibles, présentés dans la figure 10.2.

Dans l'un des cas, a et b se réfèrent à deux objets différents qui ont la même valeur. Dans le second cas, ils se réfèrent au même objet.
Pour vérifier si deux variables font référence au même objet, vous pouvez utiliser l'opérateur is.
>>> a = 'banane'
>>> b = 'banane'
>>> a is b
TrueDans cet exemple, Python a créé un seul objet chaîne de caractères et tant a que b se réfèrent à lui. Mais lorsque vous créez deux listes, vous obtenez deux objets :
>>> a = [1, 2, 3]
>>> b = [1, 2, 3]
>>> a is b
FalseAinsi, le diagramme d'état ressemble à la figure 10.3.
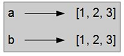
Dans ce cas, nous dirions que les deux listes sont équivalentes, parce qu'elles ont les mêmes éléments, mais pas identiques, car il ne s'agit pas d'un même objet. Si deux objets sont identiques, ils sont aussi équivalents, mais s'ils sont équivalents, ils ne sont pas nécessairement identiques.
Jusqu'à présent, nous avons utilisé « objet » et « valeur » de façon interchangeable, mais dire qu'un objet a une valeur est plus exact. Si vous évaluez [1, 2, 3], vous obtenez un objet liste dont la valeur est une séquence d'entiers. Si une autre liste a les mêmes éléments, on dit qu'elle a la même valeur, mais ce n'est pas le même objet.
10-11. Aliasing▲
Si a se réfère à un objet et si vous écrivez b = a, alors les deux variables font référence au même objet :
>>> a = [1, 2, 3]
>>> b = a
>>> b is a
TrueLe diagramme d'état ressemble à la figure 10.4.
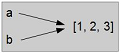
L'association entre une variable et un objet s'appelle une référence. Dans cet exemple, il existe deux références vers le même objet.
Un objet ayant plus d'une référence a plus d'un nom, donc nous disons que l'objet est un alias.
Si l'alias de l'objet est mutable, les modifications apportées à un alias affectent l'autre :
>>> b[0] = 42
>>> a
[42, 2, 3]Bien que ce comportement puisse être utile, il est source d'erreurs. En général, il est plus sûr d'éviter l'aliasing lorsque vous travaillez avec des objets modifiables.
Pour les objets immuables comme les chaînes, l'aliasing ne pose pas autant de problèmes. Dans cet exemple :
a = 'banane'
b = 'banane'cela ne change presque rien si a et b se réfèrent à la même chaîne de caractères ou non.
10-12. Arguments de type liste▲
Lorsque vous passez une liste à une fonction, la fonction reçoit une référence vers la liste. Si la fonction modifie la liste, l'appelant voit la modification. Par exemple, supprimer_premier supprime le premier élément d'une liste :
def supprimer_premier(t):
del t[0]Voici comment elle est utilisée :
>>> lettres = ['a', 'b', 'c']
>>> supprimer_premier(lettres)
>>> lettres
['b', 'c']Le paramètre t et la variable lettres sont des alias pour le même objet. Le diagramme de pile ressemble à la figure 10.5.
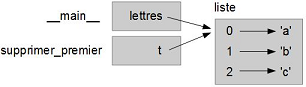
Comme la liste est partagée par deux structures, je l'ai représentée entre les deux.
Il est important de faire la distinction entre les opérations qui modifient des listes et les opérations qui créent de nouvelles listes. Par exemple, la méthode append modifie une liste, mais l'opérateur + crée une nouvelle liste :
>>> t1 = [1, 2]
>>> t2 = t1.append(3)
>>> t1
[1, 2, 3]
>>> t2
Noneappend modifie la liste et renvoie None.
>>> t3 = t1 + [4]
>>> t1
[1, 2, 3]
>>> t3
[1, 2, 3, 4]
>>> t1L'opérateur + crée une nouvelle liste et laisse la liste initiale inchangée.
Cette différence est importante lorsque vous écrivez des fonctions qui sont censées modifier des listes. Par exemple, cette fonction ne supprime pas le premier élément d'une liste :
def mauvaise_supprimer_premier(t):
t = t[1:] # ERRONÉ !L'opérateur de tranche crée une nouvelle liste et l'affectation fait de t la référence de cette liste, mais cela n'a aucun impact sur l'appelant.
>>> t4 = [1, 2, 3]
>>> mauvaise_supprimer_premier(t4)
>>> t4
[1, 2, 3]Au début de mauvaise_supprimer_premier, t et t4 se réfèrent à la même liste. À la fin, t se réfère à une nouvelle liste, mais t4 fait toujours référence à la liste originale non modifiée.
Une autre possibilité consiste à écrire une fonction qui crée et retourne une nouvelle liste. Par exemple, tail renvoie tous les éléments d'une liste, sauf le premier :
def tail(t):
return t[1:]Cette fonction laisse la liste originale non modifiée. Voici comment l'utiliser :
>>> lettres = ['a', 'b', 'c']
>>> reste = tail(lettres)
>>> reste
['b', 'c']10-13. Débogage▲
L'utilisation négligente des listes (et d'autres objets mutables) peut conduire à de longues heures de débogage. Voici quelques pièges courants et des moyens de les éviter.
-
La majorité des méthodes de liste modifient l'argument et retournent None. Les méthodes de chaînes, en revanche, renvoient une nouvelle chaîne et laissent l'original inchangé.
Si vous êtes habitué à écrire pour les chaînes de caractères du code comme ceci :Sélectionnezmot=mot.strip()Comme sort renvoie None, il est très probable que la prochaine opération que vous effectuerez avec t échouera.
Avant d'utiliser des méthodes et des opérateurs de listes, vous devez lire attentivement la documentation et ensuite les tester en mode interactif. -
Choisissez une syntaxe et tenez-vous-y.
Une partie du problème avec les listes est qu'il y a trop de façons de faire les choses. Par exemple, pour supprimer un élément d'une liste, vous pouvez utiliser pop, remove, del, ou même une affectation de tranche.
Pour ajouter un élément, vous pouvez utiliser la méthode append ou l'opérateur +. En supposant que t est une liste et x est un élément de la liste, ces instructions sont correctes :Sélectionnezt.append(x) t=t+[x] t+=[x]Et celles-ci sont erronées :
Sélectionnezt.append([x])# ERRONÉ !t=t.append(x)# ERRONÉ !t+[x]# ERRONÉ !t=t+x# ERRONÉ !Essayez chacun de ces exemples en mode interactif pour vous assurer que vous comprenez ce qu'ils font. Notez que seule la dernière provoque une erreur d'exécution ; les trois autres sont permises, mais elles ne font pas ce qui est recherché ici.
Faites des copies pour éviter aliasing.
Si vous souhaitez utiliser une méthode qui modifie l'argument, telle que sort, mais vous devez garder également la liste originale, vous pouvez faire une copie.Dans cet exemple, vous pouvez également utiliser la fonction interne sort, qui retourne une nouvelle liste triée et laisse l'originale inchangée.Sélectionnez>>>t=[3,1,2]>>>t2=t[:]>>>t2.sort()>>>t [3,1,2]>>>t2 [1,2,3]
>>> t2 = sorted(t)
>>> t
[3, 1, 2]
>>> t2
[1, 2, 3]10-14. Glossaire▲
- liste : une séquence de valeurs.
- élément : une des valeurs d'une liste (ou une autre séquence), également appelées items.
- liste imbriquée : une liste qui est un élément d'une autre liste.
- accumulateur : une variable utilisée dans une boucle pour additionner ou accumuler un résultat.
- affectation augmentée : une instruction qui met à jour la valeur d'une variable en utilisant un opérateur comme +=.
- réduire : un modèle de traitement qui parcourt une séquence et accumule les éléments dans un seul résultat.
- mapper : un modèle de traitement qui parcourt une séquence et effectue une opération sur chaque élément.
- filtrer : un modèle de traitement qui parcourt une liste et sélectionne les éléments qui satisfont certains critères.
- objet : quelque chose auquel une variable peut se référer. Un objet a un type et une valeur.
- équivalent : ayant la même valeur.
- identique : être le même objet (ce qui implique l'équivalence).
- référence : l'association entre une variable et sa valeur.
- aliasing : une circonstance où deux ou plusieurs variables font référence au même objet.
- délimiteur : un caractère ou une chaîne indiquant où une chaîne devrait être scindée.
10-15. Exercices▲
Vous pouvez télécharger les solutions de ces exercices à l'adresse list_exercises.py.
Exercice 1
Écrivez une fonction appelée nested_sum qui prend une liste de listes d'entiers et additionne les éléments de toutes les listes imbriquées. Par exemple :
>>> t = [[1, 2], [3], [4, 5, 6]]
>>> nested_sum(t)
21Écrivez une fonction appelée cumsum qui prend une liste de nombres et renvoie la somme cumulative ; c'est-à-dire une nouvelle liste où le n-ième élément est la somme des premiers n + 1 éléments de la liste originale. Par exemple :
>>> t = [1, 2, 3]
>>> cumsum(t)
[1, 3, 6]Exercice 3
Écrivez une fonction appelée middle qui prend une liste et renvoie une nouvelle liste qui contient tous les éléments, sauf le premier et le dernier. Par exemple :
>>> t = [1, 2, 3, 4]
>>> middle(t)
[2, 3]Exercice 4
Écrivez une fonction appelée chop qui prend une liste, la modifie en supprimant le premier et le dernier élément, et retourne None. Par exemple :
>>> t = [1, 2, 3, 4]
>>> chop(t)
>>> t
[2, 3]Exercice 5
Écrivez une fonction appelée is_sorted qui prend une liste comme paramètre et renvoie True si la liste est triée par ordre croissant et False sinon. Par exemple :
>>> is_sorted([1, 2, 2])
True
>>> is_sorted(['b', 'a'])
FalseDeux mots sont des anagrammes si vous pouvez réarranger les lettres de l'un pour en former l'autre (par exemple ALEVIN et NIVELA sont des anagrammes). Écrivez une fonction appelée is_anagram qui prend deux chaînes et renvoie True si ce sont des anagrammes.
Écrivez une fonction appelée has_duplicates qui prend une liste et renvoie True s'il y a au moins un élément qui apparaît plus d'une fois. La méthode ne devrait pas modifier la liste originale.
Exercice 8
Cet exercice est relatif à ce que l'on appelle le paradoxe des anniversaires, au sujet duquel vous pouvez lire sur https://fr.wikipedia.org/wiki/Paradoxe_des_anniversaires .
S'il y a 23 étudiants dans votre classe, quelles sont les chances que deux d'entre vous aient le même anniversaire ? Vous pouvez estimer cette probabilité en générant des échantillons aléatoires de 23 anniversaires et en vérifiant les correspondances. Indice : vous pouvez générer des anniversaires aléatoires avec la fonction randint du module random.
Vous pouvez télécharger ma solution à l'adresse birthday.py.
Exercice 9
Écrivez une fonction qui lit le fichier mots.txt du chapitre précédent et construit une liste avec un élément par mot. Écrivez deux versions de cette fonction, l'une qui utilise la méthode append et l'autre en utilisant la syntaxe t = t + [x]. Laquelle prend plus de temps pour s'exécuter ? Pourquoi ? Solution : wordlist.py.
Pour vérifier si un mot se trouve dans la liste de mots, vous pouvez utiliser l'opérateur in , mais cela serait lent, car il vérifie les mots un par un dans l'ordre de leur apparition.
Si les mots sont dans l'ordre alphabétique, nous pouvons accélérer les choses avec une recherche dichotomique (aussi connue comme recherche binaire), qui est similaire à ce que vous faites quand vous recherchez un mot dans le dictionnaire. Vous commencez au milieu et vérifiez si le mot que vous recherchez vient avant le mot du milieu de la liste. Si c'est le cas, vous recherchez de la même façon dans la première moitié de la liste. Sinon, vous regardez dans la seconde moitié.
Dans les deux cas, vous divisez en deux l'espace de recherche restant. Si la liste de mots a 130 557 mots, il faudra environ 17 étapes pour trouver le mot ou conclure qu'il n'y est pas.
Écrivez une fonction appelée in_bisect qui prend une liste triée et une valeur cible et renvoie l'index de la valeur dans la liste si elle s'y trouve, ou None si elle n'y est pas. N'oubliez pas qu'il faut préalablement trier la liste par ordre alphabétique pour que cet algorithme puisse fonctionner ; vous gagnerez du temps si vous commencez par trier la liste en entrée et la stockez dans un nouveau fichier (vous pouvez utiliser la fonction sort de votre système d'exploitation si elle existe, ou sinon le faire en Python), vous n'aurez ainsi besoin de le faire qu'une seule fois.
Ou alors vous pouvez lire la documentation du module bisect et l'utiliser ! Solution : inlist.py.
Exercice 11
Un mot est anacyclique si l'on peut le lire à l'envers ou à l'endroit, généralement la signification étant différente selon le sens de lecture. (Par exemple, « NEZ » et « ZEN », « REGAGNER » et « RENGAGER », ou « LAMINA » et « ANIMAL ») Écrivez un programme qui trouve tous les anacycliques dans la liste de mots. Indice 1: utilisez la recherche dichotomique étudiée à l'exercice précédent pour recherche un mot dans une liste. Indice 2 : il y a près de 300 mots de plus de deux lettres de ce type dans notre liste. Solution : reverse_pair.py.
Exercice 12
Deux mots s'« entrelacent » si vous pouvez former un nouveau mot en prenant des lettres alternées de chacun. Par exemple, les mots « FADE » et « RUES » s' « entrelacent » pour former « FRAUDEES ». Indice: les mots « composants » n'ont pas nécessairement le même nombre de lettres, le premier peut avoir une lettre de plus que le second. Ainsi, les mots « ACRES » et « CODE » peuvent former « ACCORDEES ». Solution : interlock.py. Référence : Cet exercice est inspiré par un exemple sur http://puzzlers.org.
- Écrivez un programme qui trouve toutes les paires de mots qui s'« entrelacent » . Indice : ne pas énumérer toutes les paires, il y en a plus de 400 en n'acceptant que des « composants » d'au moins 3 lettres !
- Pouvez-vous trouver tous les trios de mots qui s'« entrelacent » par trois ; c'est-à-dire que, en partant de la première, deuxième ou troisième lettre du mot résultat, on obtient trois mots en prenant une lettre toutes les trois lettres ? Indice 1 : la formulation employée ici est susceptible de faire penser à un algorithme bien plus efficace : n'essayez pas toutes les combinaisons de mots courts pour trouver des mots longs, ce pourrait être très lent ; partez plutôt des mots longs et voyez si vous pouvez les décomposer trois mots appartenant à la liste. Indice 2 : contrairement à ce que l'on pourrait penser de prime abord, il y en a beaucoup (plus de 700).
