


11. Dictionnaires▲
Ce chapitre présente un autre type interne appelé dictionnaire. Les dictionnaires sont une des meilleures fonctionnalités de Python ; ce sont les blocs de construction de nombreux algorithmes efficaces et élégants.
11-1. Un dictionnaire est un mappage▲
Un dictionnaire ressemble à une liste, mais il est plus général. Dans une liste, les indices doivent être des nombres entiers ; dans un dictionnaire, ils peuvent être de (presque) n'importe quel type.
Un dictionnaire contient une collection d'indices, qui sont appelés clés, et une collection de valeurs. Chaque clé est associée à une valeur unique. L'association entre une clé et une valeur est appelée une paire clé-valeur ou parfois un item.
En langage mathématique, un dictionnaire représente un mappage de clés vers des valeurs, donc vous pouvez également dire que chaque clé « correspond à » une valeur. À titre d'exemple, nous allons construire un dictionnaire qui mappe des mots français vers des mots espagnols, si bien que tant les clés que les valeurs seront des chaînes de caractères.
La fonction dict crée un nouveau dictionnaire sans aucun élément. Comme dict est le nom d'une fonction interne, vous devez éviter de l'utiliser comme nom de variable.
>>> fr_vers_es = dict()
>>> fr_vers_es
{}Les accolades {} représentent un dictionnaire vide. Pour ajouter des éléments au dictionnaire, vous pouvez utiliser des crochets :
>>> fr_vers_es['un'] = 'uno'Cette ligne crée un élément qui fait correspondre la clé 'un' à la valeur 'uno'. Si nous affichons à nouveau le dictionnaire, nous voyons une paire clé-valeur avec un caractère deux-points entre la clé et la valeur :
>>> fr_vers_es
{'un': 'uno'}Ce format en sortie est également un format en entrée possible. Par exemple, vous pouvez créer un nouveau dictionnaire avec trois éléments :
>>> fr_vers_es = {'un': 'uno', 'deux': 'dos', 'trois': 'tres'}Mais si vous affichez fr_vers_es, vous pourriez être surpris :
>>> fr_vers_es
{'un': 'uno', 'trois': 'tres', 'deux': 'dos'}L'ordre des paires clé-valeur pourrait ne pas être le même. Si vous tapez le même exemple sur votre ordinateur, vous obtiendrez peut-être un résultat différent. En général, l'ordre des éléments dans un dictionnaire est imprévisible.
Mais cela ne pose aucun problème parce que les éléments d'un dictionnaire ne sont jamais indexés avec des indices entiers. Au lieu de cela, vous utilisez les clés pour rechercher les valeurs correspondantes :
>>> fr_vers_es['deux']
'dos'La clé 'deux' mappe toujours vers la valeur 'dos', et l'ordre des éléments n'a donc aucune importance.
Si la clé n'existe pas dans le dictionnaire, vous obtenez une exception :
>>> fr_vers_es['quatre']
KeyError: 'quatre'La fonction len peut être utilisée sur les dictionnaires ; elle renvoie le nombre de paires clé-valeur :
>>> len(fr_vers_es)
3L'opérateur in aussi fonctionne sur des dictionnaires ; il vous indique si quelque chose apparaît comme une clé dans le dictionnaire (mais pas si cette chose figure parmi les valeurs).
>>> 'un' in fr_vers_es
True
>>> 'uno' in fr_vers_es
FalsePour voir si quelque chose apparaît comme une valeur dans un dictionnaire, vous pouvez utiliser la méthode values, qui retourne une collection de valeurs, et ensuite utiliser l'opérateur in :
>>> valeurs = fr_vers_es.values()
>>> 'uno' in valeurs
TrueL'opérateur in utilise des algorithmes différents pour les listes et les dictionnaires. Pour les listes, il recherche les éléments de la liste dans l'ordre, comme nous l'avons vu dans la section 8.6Recherche. Au fur et à mesure que la liste s'allonge, le temps de recherche augmente proportionnellement à sa taille.
Pour les dictionnaires, Python utilise un algorithme appelé table de hachage qui a une propriété remarquable : l'opérateur in prend à peu près le même temps, quel que soit le nombre d'éléments dans le dictionnaire. J'explique comment c'est possible dans la section B.4Tables de hachage (annexe à la fin de ce livre), mais l'explication pourrait ne pas être compréhensible avant que vous n'ayez lu encore quelques chapitres.
11-2. Un dictionnaire comme une collection de compteurs▲
Supposons que vous ayez une chaîne de caractères et que vous vouliez compter le nombre de fois où apparaît chaque lettre. Il y a plusieurs façons de faire cela :
- Vous pourriez créer 26 variables, une pour chaque lettre de l'alphabet. Ensuite, vous pourriez parcourir la chaîne et, pour chaque caractère, incrémenter le compteur correspondant, probablement en utilisant des conditions enchaînées ;
- Vous pourriez créer une liste de 26 éléments. Ensuite, vous pouvez convertir chaque caractère en un nombre (en utilisant la fonction interne ord), utiliser ce nombre comme un index de liste, et incrémenter le compteur approprié ;
- Vous pourriez créer un dictionnaire avec des caractères comme clés et des compteurs comme valeurs correspondantes. La première fois que vous trouvez un caractère, vous ajouteriez un élément au dictionnaire. Ensuite, vous incrémenteriez la valeur d'un élément existant.
Chacune de ces options effectue le même calcul, mais chacune d'entre elles met en œuvre ce calcul d'une manière différente.
Une implémentation ou mise en œuvre est une façon pratique d'effectuer un calcul ; certaines implémentations sont meilleures qu'autres. Par exemple, un avantage de la mise en œuvre du dictionnaire est que nous n'avons pas besoin de savoir à l'avance quelles lettres apparaissent dans la chaîne de caractères et nous ne devons réserver de la place mémoire que pour les lettres qui apparaissent réellement.
Voici à quoi pourrait ressembler le code :
def histogramme(s):
d = dict()
for c in s:
if c not in d:
d[c] = 1
else:
d[c] += 1
return dLe nom de la fonction est histogramme, qui est un terme statistique pour une collection de compteurs (ou de fréquences).
La première ligne de la fonction crée un dictionnaire vide. La boucle for parcourt la chaîne. À chaque passage dans la boucle, si le caractère c n'est pas dans le dictionnaire, nous allons créer un nouvel élément ayant la clé c et la valeur initiale 1 (puisque nous avons trouvé cette lettre une fois). Si c existe déjà dans le dictionnaire, alors on incrémente d[c].
Voici comment cela fonctionne :
>>> h = histogramme('brontosaure')
>>> h
{'a': 1, 'b': 1, 'e': 1, 'o': 2, 'n': 1, 's': 1, 'r': 2, 'u': 1, 't': 1}L'histogramme indique que les lettres 'a', 'b' et 'e' apparaissent une fois ; 'o' apparaît deux fois, et ainsi de suite.
Les dictionnaires ont une méthode appelée get qui prend une clé et une valeur par défaut. Si la clé apparaît dans le dictionnaire, get renvoie la valeur correspondante ; sinon, elle renvoie la valeur par défaut. Par exemple :
>>> h = histogramme('a')
>>> h
{'a': 1}
>>> h.get('a', 0)
1
>>> h.get('b', 0)
0À titre d'exercice, utilisez la méthode get pour écrire histogramme de façon plus concise. Vous devriez être en mesure d'éliminer l'instruction if.
11-3. Boucles et dictionnaires▲
Si vous utilisez un dictionnaire dans une instruction for, elle parcourt les clés du dictionnaire. Par exemple, print_hist affiche chaque clé et la valeur correspondante :
def print_hist(h):
for c in h:
print(c, h[c])Voici à quoi ressemble l'affichage :
>>> h = histogramme('perroquet')
>>> print_hist(h)
e 2
o 1
q 1
p 1
r 2
u 1
t 1Encore une fois, les clés ne sont dans aucun ordre particulier. Pour parcourir les clés dans l'ordre trié, vous pouvez utiliser la fonction interne sorted :
>>> for key in sorted(h):
... print(key, h[key])
'e', 2
'o', 1
'p', 1
'q', 1
'r', 2
't', 1
'u', 111-4. Recherche inversée▲
Étant donné un dictionnaire d et une clé k, il est facile de trouver la valeur correspondante v = d[k]. Cette opération s'appelle une recherche.
Mais que faire si vous avez v et que vous voulez trouver k ? Vous avez deux problèmes : d'abord, il pourrait y avoir plus d'une clé qui correspond à la valeur v. En fonction de l'application, vous pourriez être en mesure d'en choisir une, ou vous pourriez avoir à faire une liste qui les contient toutes. Deuxièmement, il n'y a aucune syntaxe simple pour faire une recherche inversée ; vous devez faire une recherche en parcourant les éléments un par un.
Voici une fonction qui prend une valeur et renvoie la première clé qui correspond à cette valeur :
def recherche_inverse(d, v):
for k in d:
if d[k] == v:
return k
raise LookupError()Cette fonction est encore un autre exemple du modèle de recherche, mais elle utilise une fonctionnalité que nous n'avons pas vue avant, raise. L'instruction raise provoque une exception ; dans ce cas, elle génère une LookupError, qui est une exception interne utilisée pour indiquer qu'une opération de recherche a échoué.
Si nous arrivons à la fin de la boucle, cela signifie que v ne figure pas comme une valeur dans le dictionnaire, donc nous générons une exception.
Voici un exemple d'une recherche inversée réussie :
>>> h = histogramme('perroquet')
>>> key = recherche_inverse(h, 2)
>>> key
'e'Et une qui a échoué :
>>> key = recherche_inverse(h, 3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 5, in recherche_inverse
LookupErrorL'effet lorsque vous générez une exception est le même que lorsque Python en génère une : une trace et un message d'erreur sont affichés.
L'instruction raise peut prendre un message d'erreur détaillé comme un argument optionnel. Par exemple :
>>> raise LookupError('valeur inexistante dans le dictionnaire')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
LookupError: valeur inexistante dans le dictionnaireUne recherche inversée est beaucoup plus lente qu'une recherche directe ; si vous devez le faire souvent, ou si le dictionnaire devient grand, la performance de votre programme se détériorera.
11-5. Dictionnaires et listes▲
Des listes peuvent apparaître comme valeurs dans un dictionnaire. Par exemple, si vous avez un dictionnaire qui fait correspondre des lettres à des fréquences, vous voudrez peut-être l'inverser ; autrement dit, créer un dictionnaire qui fait correspondre des fréquences aux lettres. Comme il se peut qu'il y ait plusieurs lettres ayant la même fréquence, chaque valeur dans le dictionnaire inversé doit être une liste de lettres.
Voici une fonction qui inverse un dictionnaire :
def invert_dict(d):
inverse = dict()
for key in d:
val = d[key]
if val not in inverse:
inverse[val] = [key]
else:
inverse[val].append(key)
return inverseÀ chaque passage dans la boucle, key reçoit une clé du dictionnaire d et val reçoit la valeur correspondante. Si val ne se trouve pas dans inverse, cela signifie que nous ne l'avons pas encore rencontrée, donc nous créons un nouvel élément et l'initialisons avec un singleton (une liste qui contient un seul élément). Sinon, nous avons déjà rencontré cette valeur, alors nous ajoutons la clé correspondante à la fin de la liste.
Voici un exemple :
>>> hist = histogramme('perroquet')
>>> hist
{'e': 2, 'o': 1, 'q': 1, 'p': 1, 'r': 2, 'u': 1, 't': 1}
>>> inverse = invert_dict(hist)
>>> inverse
{1: ['o', 'q', 'p', 'u', 't'], 2: ['e', 'r']}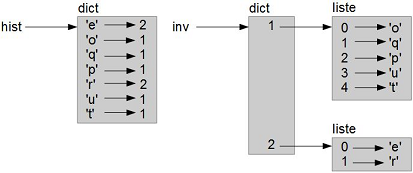
La Figure 11.1 est un diagramme d'état montrant hist et inverse. Un dictionnaire est représenté comme un rectangle avec le type dict au-dessus et les paires clé-valeur à l'intérieur. Si les valeurs sont des nombres entiers, des flottants ou des chaînes de caractères, je les dessine à l'intérieur du rectangle, mais généralement je dessine les listes en dehors du rectangle, juste pour garder le schéma simple.
Les listes peuvent être des valeurs dans un dictionnaire, comme le montre cet exemple, mais elles ne peuvent pas être des clés. Voici ce qui se passe si vous essayez :
>>> t = [1, 2, 3]
>>> d = dict()
>>> d[t] = 'oups'
Traceback (most recent call last):
File "<stdin>", line 1, in ?
TypeError: list objects are unhashableJ'ai mentionné plus tôt qu'un dictionnaire est mis en œuvre en utilisant une table de hachage et cela signifie que les clés doivent être hachables.
Une fonction de hachage est une fonction qui prend une valeur (de n'importe quel type) et retourne un entier. Les dictionnaires utilisent ces entiers, appelés valeurs de hachage, pour stocker et rechercher des paires clé-valeur.
Ce système fonctionne très bien si les clés sont immuables. Mais si les clés sont modifiables, comme les listes, de gros problèmes se posent. Par exemple, lorsque vous créez une paire clé-valeur, Python hache la clé et la stocke dans l'emplacement correspondant. Si vous modifiez la clé, puis la hachez à nouveau, elle ira à un endroit différent. Dans ce cas, vous pourriez avoir deux entrées pour la même clé, ou vous pourriez ne pas être en mesure de trouver une clé. Quoi qu'il arrive, le dictionnaire ne fonctionnera pas correctement.
Voilà pourquoi les clés doivent être « hachables », et pourquoi les types modifiables comme les listes ne le sont pas. La façon la plus simple de contourner cette limitation est d'utiliser des tuples, que nous verrons dans le chapitre suivant.
Puisque les dictionnaires sont modifiables, ils ne peuvent pas servir de clés, mais ils peuvent être utilisés comme valeurs.
11-6. Mémos▲
Si vous avez joué un peu avec la fonction fibonacci de la section 6.7Encore un exemple, vous avez peut-être remarqué que plus l'argument que vous fournissez est grand, plus la durée d'exécution de la fonction augmente. En outre, la durée d'exécution augmente très rapidement :
|
Exemples de durée d'exécution de la recherche de nombre de Fibonacci |
|
|---|---|
|
Nombre de Fibonacci |
Durée d'exécution |
|
20 |
0m0.109s |
|
30 |
0m1.295s |
|
40 |
2m28.965s |
|
100 (estimation) |
Milliards d'années |
Pour comprendre pourquoi, examinons la figure 11.2, qui montre le graphe des appels pour fibonacci avec n = 4 :
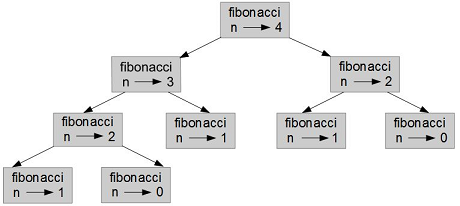
Un graphe d'appels montre un ensemble de structures de fonction, avec des lignes reliant chaque structure aux structures des fonctions qu'elle appelle. Au sommet du graphe, fibonacci avec n = 4 appelle fibonacci avec n = 3 et avec n = 2. À son tour, fibonacci avec n = 3 appelle fibonacci avec n = 2 et avec n = 1. Et ainsi de suite.
Comptez le nombre de fois où fibonacci(0) et fibonacci(1) sont appelées. C'est une solution inefficace du problème, et cela devient pire au fur et à mesure que l'argument devient plus grand.
Une solution consiste à garder la trace des valeurs qui ont déjà été calculées en les stockant dans un dictionnaire. Une valeur calculée précédemment qui est stockée pour une utilisation ultérieure est appelée un mémo (ou un cache). Voici une version « mémoïsée » ou avec mise en cache de fibonacci :
connu = {0:0, 1:1}
def fibonacci(n):
if n in connu:
return connu[n]
res = fibonacci(n - 1) + fibonacci(n - 2)
connu[n] = res
return resconnu est un dictionnaire qui permet de garder la trace des nombres de Fibonacci que nous connaissons déjà. Il commence par deux éléments : 0 mappe vers 0 et 1 mappe vers 1.
Chaque fois que fibonacci est appelée, elle vérifie connu. Si le résultat s'y trouve déjà, elle peut le renvoyer immédiatement. Sinon, elle doit calculer la nouvelle valeur, l'ajouter au dictionnaire, et la renvoyer.
Si vous exécutez cette version de fibonacci et la comparez avec l'original, vous trouverez qu'elle est beaucoup plus rapide.
11-7. Variables globales▲
Dans l'exemple précédent, connu est créé en dehors de la fonction, de sorte qu'il appartient à la structure spéciale appelée __main__. Les variables dans __main__ sont parfois appelées globales, car elles peuvent être accédées à partir de n'importe quelle fonction. Contrairement aux variables locales, qui disparaissent lorsque leur fonction se termine, les variables globales persistent d'un appel de fonction à l'autre.
Il est courant d'utiliser des variables globales pour des drapeaux ou flags ; c'est-à-dire des variables booléennes qui indiquent (ou « signalent ») si une condition est vraie. Par exemple, certains programmes utilisent un drapeau nommé verbose (« bavard » ou « verbeux ») pour contrôler le niveau de détail dans la sortie :
verbose = True
def exemple1():
if verbose:
print('Exécuter exemple1')Si vous essayez de réaffecter une variable globale, vous pourriez être surpris. L'exemple suivant est censé garder une trace afin de savoir si la fonction a été appelée :
est_appelee = False
def exemple2():
est_appelee = True # ERRONÉMais si vous l'exécutez, vous verrez que la valeur de est_appelee ne change pas. Le problème est que exemple2 crée une nouvelle variable locale nommée est_appelee. La variable locale disparaît lorsque la fonction se termine, et n'a aucun effet sur la variable globale.
Pour réaffecter une variable globale dans une fonction, vous devez déclarer la variable comme étant globale avant de l'utiliser :
est_appelee = False
def exemple2():
global est_appelee
est_appelee = TrueL'instruction global dit à peu près ceci à l'interpréteur : « Dans cette fonction, quand je dis est_appelee, je parle de la variable globale ; n'en crée pas une version locale. »
Voici un exemple qui tente de mettre à jour une variable globale :
compteur = 0
def exemple3():
compteur = compteur + 1 # ERRONÉSi vous l'exécutez, vous obtenez :
UnboundLocalError: local variable 'compteur' referenced before assignmentPython suppose que compteur est une variable locale, et, selon cette hypothèse, que vous lisez celle-ci avant de l'écrire. La solution, encore une fois, est de déclarer la variable compteur comme étant globale.
def exemple3():
global compteur
compteur += 1Si une variable globale fait référence à une valeur modifiable (par exemple l'élément d'une liste ou d'un dictionnaire), vous pouvez modifier la valeur sans déclarer la variable :
connu = {0:0, 1:1}
def exemple4():
connu[2] = 1Ainsi, vous pouvez ajouter, supprimer et remplacer des éléments d'une liste ou un dictionnaire global, mais si vous voulez réaffecter la variable, vous devez déclarer cela :
def exemple5():
global connu
connu = dict()Les variables globales peuvent être utiles, mais si vous en avez beaucoup, et que vous les modifiez fréquemment, elles peuvent rendre les programmes difficiles à déboguer.
11-8. Débogage▲
Lorsque vous travaillez avec de plus grands ensembles de données, il peut devenir difficile de déboguer en affichant et en vérifiant la sortie à la main. Voici quelques suggestions pour déboguer de grands ensembles de données.
Réduire la taille des données en entrée
- Si possible, réduisez la taille de l'ensemble de données. Par exemple, si le programme lit un fichier texte, commencez avec seulement les 10 premières lignes, ou avec le plus petit exemple que vous puissiez trouver. Vous pouvez soit éditer les fichiers mêmes, ou (mieux) modifier le programme pour qu'il ne lise que les n premières lignes.
- Si une erreur survient, vous pouvez réduire n à la plus petite valeur qui provoque l'erreur. Ensuite, vous pouvez augmenter n progressivement au fur et à mesure que vous trouvez et corrigez les erreurs.
Vérifier les résumés et les types
- Au lieu d'afficher et de vérifier l'ensemble des données, pensez à afficher des résumés des données : par exemple, le nombre d'éléments dans un dictionnaire ou le total d'une liste de nombres.
- Une cause fréquente d'erreurs d'exécution est une valeur qui n'est pas du bon type. Pour déboguer ce genre d'erreur, souvent il suffit d'afficher le type d'une valeur.
Écrire des contrôles automatisés
- Parfois, vous pouvez écrire du code pour vérifier automatiquement les erreurs. Par exemple, si vous calculez la moyenne d'une liste de nombres, vous pourriez vérifier que le résultat n'est pas plus grand que le plus grand élément de la liste ou plus petit que le plus petit élément. Cela est appelé une « vérification de vraisemblance », car on détecte des résultats « invraisemblables ».
- Un autre type de vérification compare les résultats de deux calculs différents pour voir s'ils sont compatibles. Cela s'appelle un « contrôle de cohérence ».
Formater la sortie
- Le formatage de la sortie du débogage peut faciliter le repérage d'une erreur. Nous avons vu un exemple dans la section 6.9Débogage. Le module pprint fournit une fonction pprint qui affiche les types internes dans un format plus lisible (pprint signifie « pretty print» - affichage joli).
Encore une fois, le temps que vous passez à construire des échafaudages peut réduire le temps que vous passez à déboguer.
11-9. Glossaire▲
- mappage : une relation dans laquelle chaque élément d'un ensemble est associé à un élément d'un autre ensemble.
- dictionnaire : un mappage de clés vers leurs valeurs correspondantes.
- paire clé-valeur : la représentation du mappage d'une clé vers une valeur.
- clé : un objet qui apparaît dans un dictionnaire comme la première partie d'une paire clé-valeur.
- valeur : un objet qui apparaît dans un dictionnaire comme la seconde partie d'une paire clé-valeur. Il s'agit ici d'une utilisation plus spécifique que précédemment du mot « valeur ».
- implémentation (mise en œuvre) : une façon d'effectuer un calcul dans le cadre d'un programme informatique.
- hashtable (table de hachage) : l'algorithme utilisé pour mettre en œuvre des dictionnaires en Python.
- fonction de hachage : une fonction utilisée par une table de hachage pour calculer l'emplacement d'une clé.
- hachable : un type qui a une fonction de hachage. Les types immuables comme les entiers, les flottants et les chaînes de caractères sont hachables ; les types modifiables comme les listes et les dictionnaires ne le sont pas.
- recherche : une opération de dictionnaire qui prend une clé et trouve la valeur correspondante.
- recherche inversée : une opération de dictionnaire qui prend une valeur et trouve une ou plusieurs clés qui lui sont associées.
- instruction raise : une instruction qui génère (volontairement) une exception.
- singleton : une liste (ou une autre séquence) avec un seul élément.
- graphe des appels : un diagramme qui montre chaque structure créée pendant l'exécution d'un programme, avec une flèche de chaque appelant à chaque appelé.
- mémo ou cache : une valeur calculée stockée pour éviter de refaire inutilement le même calcul.
- variable globale : une variable définie en dehors d'une fonction. Les variables globales peuvent être accessibles à partir de toute fonction.
- instruction global : une instruction qui déclare un nom variable comme étant global.
- drapeau ou flag : une variable booléenne utilisée pour indiquer si une condition est vraie.
- déclaration : une instruction, comme global, qui transmet à l'interpréteur une information au sujet d'une variable.
11-10. Exercices▲
Exercice 1
Écrivez une fonction qui lit les mots dans mots.txt et les stocke comme clés dans un dictionnaire. Peu importent les valeurs. Ensuite, vous pouvez utiliser l'opérateur in comme un moyen rapide pour vérifier si une chaîne se trouve dans le dictionnaire.
Si vous avez fait l'exercice 10 du chapitre précédent, vous pouvez comparer la durée d'exécution de cette mise en œuvre avec celle utilisant l'opérateur de liste in et celle de la recherche dichotomique.
Lisez la documentation de la méthode de dictionnaire setdefault et utilisez-la pour écrire une version plus concise de invert_dict. Solution : invert_dict.py.
Exercice 3
Transformez la fonction d'Ackermann de l'exercice 2 du chapitre 6 en une fonction « mémoïsée » et voyez si la « mémoïsation » permet d'évaluer la fonction avec des arguments plus grands. Indice : aucun. Solution : ackermann_memo.py.
Exercice 4
Si vous avez fait l'exercice 7 du chapitre 10, vous avez déjà une fonction nommée has_duplicates qui prend comme paramètre une liste et renvoie True s'il existe un objet qui apparaît plus d'une fois dans la liste.
Utilisez un dictionnaire pour écrire une version plus rapide et plus simple de has_duplicates. Solution : has_duplicates.py.
Deux mots forment « une paire par rotation » si vous pouvez effectuer la rotation d'un d'entre eux avec un chiffre de César pour en obtenir l'autre (voir rotate_word dans l'exercice 5 du chapitre 8).
Écrivez un programme qui lit une liste de mots et trouve toutes les paires par rotation. Solution : rotate_pairs.py.
Exercice 6
Trouvez, dans notre liste de mots, des mots de cinq lettres tels que, si vous retirez la première lettre, le nouveau mot de quatre lettres obtenu figure également dans notre liste, et que si vous retirez la nouvelle première lettre, le nouveau mot de trois lettres obtenu soit également un mot de notre liste. Par exemple, le mot EPILE donne PILE puis ILE, qui sont deux mots appartenant à notre liste. Utilisez un dictionnaire pour stocker les mots de la liste et faire les recherches nécessaires. Indice : il y a plus de 250 mots dans ce cas.
